Things you should care about, but probably don't - Techie
Techie
Boldly going where lots of people already have
{kind=link}
We made a site. So what? It doesn't really matter what we did, it only matters how you use it.
...so,

All the orginal content, including text, images, video, markup and/or other code published on our website is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License, unless expressly stated otherwise.
This means Berkhamsted Imaging retains the copyright but you can use, copy and distribute elements from the site, as long as you abide by the terms of the licence and acknowledge Berkhamsted Imaging as the source.
Many of the images and photos used on our website, belong to other people. We've tried hard to ensure that our use is fair and that the authors are properly credited, by providing credit and licensing information for these image in-situ, in our markup and more fully on our dedicated credits page.
Are QR codes, a bit gimmicky? I'm not sure.
The only sensible use for a QR code seems to me to require that you print it out or put it on display somewhere. So putting them on a web-site seems mostly re-dumb-dant. Whatever. We did have a need to create and print them... so, we might aswell let you, too!
This site was built to run in HTML5 aware browsers... but with support for some older browsers, notably IE8.
The only reason that we bothered with this is because, IE8 is the last (ever) version of Internet Explorer that works (will work) with Windows XP ...and about a third of all PCs in the world are still running Windows XP.
But, this cannot last forever.
Microsoft is ending (unpaid) support for Windows XP on 08 April 2014. This event has, in some strands of the interweb, been labelled the "X-pocalypse", as it is feared are that as soon as Microsoft stops producing security patches for Windows XP, via Windows Update, an armageddon of (as yet undisclosed) security exploits for Windows XP will explode into the wild... effectively rendering the OS insecure/unusable in a network enviroment.
It remains to be seen, quite how this will pan out... but it is pretty obvious that, whatever Microsoft and the technoratti say about XP having reached the end of its lifespan, a whole LOT of computers are still going to be running it come 01 May 2014 and most of those will be connected to the internet in some way or another...
If there is a moral, it seems to be this...
- If you can, stop using Windows XP
- If you can't, at the very least, stop using Internet Explorer 8 as your browser.
Many of the technoratti sites, like GitHub dropped support for older versions of Internet Explorer some while ago and mainstream sites, including the likes of Google, are sounding the death knell for IE8.
It looks to me, like April 2014, will see a dramatic and terminal decline in the use of (and need for websites to support) IE8.
What this means to us at BIC, and to you, dear user, is that soon, but not quite yet, we will no longer be supporting IE8 either.
If you're a member of the set of humans that uses the internet (and on the basis of the current evidence, it appears you are) and you're not a Tory MP, then you may well understand what Rule 34 is already.
However, in our much fluffier world, Rule 34, is "If you can imagine it, you can create it".
What we serve up on the web is up to us. What you choose to do with it once it lands in your browser is up to you. We want you to bend our website to your will.
Greasemonkey (and its Chrome equivalent) make it easy to muck about with other people's websites. Even, if you've never written a line of code in your life, an hour or so googling and experimenting will have you doing stuff, you never realised you could. It's fun and, sometimes, useful too.
Typing sucks. Keyboards suck. Mice really suck.
I even, sort-of-hate, my fancy, multi-button, custom macro-ed up gaming mouse... even though its by far the best mouse I've ever owned.
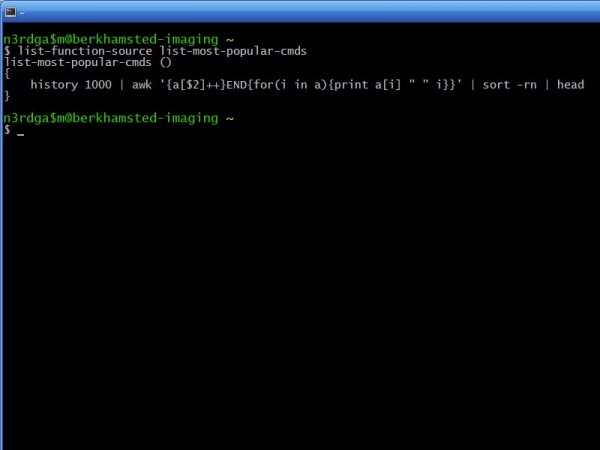
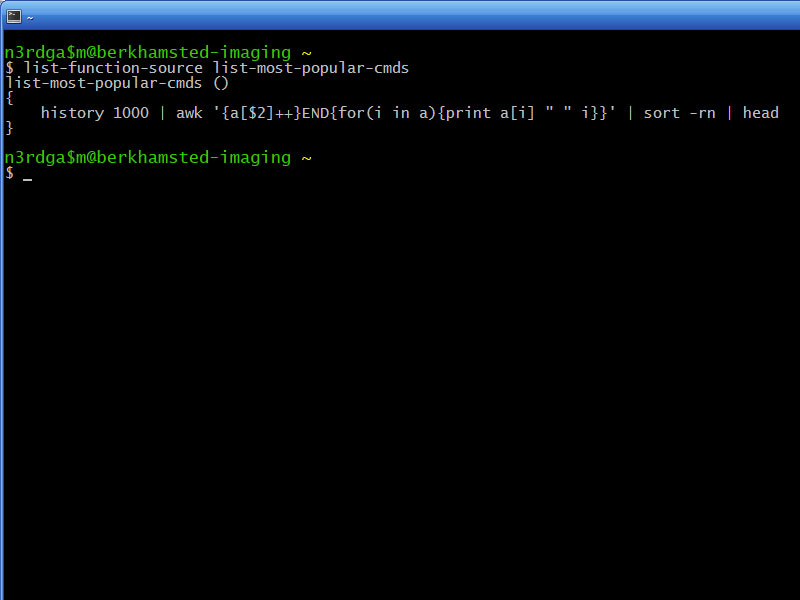
I automate everything I can. Even things I shouldn't, because it takes way longer to automate, than it would to just do it. As a result, I have legions of little bits of code, that make my life tolerable. One day, hopefully soon, I'll get round to pushing those bits that other people might also like, into the cloud.
We have an API, sort of.
But, it's not like most other API's, because it isn't publically documented or supported. Yet. And it isn't about extracting data (from us), its about sending data (to us).
So, currently it's not really an Application Programming Interface at all. More a kind of Application Data Structure, and a precursor to an API.
Essentially, the entire print ordering system on our site simply generates some JSON, which describes the relatively complex data structure necessary to define a print order. The generated JSON then gets sent to our server which does all the difficult, properitory stuff and then responds with the HTML necessary to generate appropriate payment page(s).
The JSON data structure includes refererences to the location of the user's uploaded images (rather than embedding the images, themselves), so that whilst our web interface (currently) pressumes that the user will be uploading local image files to our server; the JSON merely acts to define a URL to those images once they have been uploaded.
Therefore, you could, in theory, just
- Generate your own order JSON, which references any (accessible by us) image URLs and
- Use a tool like curl, to send it to our server
to generate an order.
What you use to produce the JSON is irrelevant... but (and hopefully obviously) as JSON is only formatted text, this opens up the possibility of
- automated order generation,
- third party web-site or application integration
- and/or offline interfaces.
There are many ways I can imagine that this could be utilised. For example:
- A simple off-line ordering application
- Pro photographers could use it to invisibly and seemlessly automate the outsourcing their customer's print orders.
- People or companies looking to do high volumes of photo prints at specially negotiated rates could use it.
Hell, I managed to bash out (geddit) a quick proof of concept for ordering from the commandline, in about 40 minutes... and most of that was looking up the parameters for curl.
If anyone is even vaguely interested in this e.mail me. Any interest in this, even if just to discuss what this makes possible and how it might be used, is likely to push it further up my list of things I might do one day.
/s